정규표현식에서 앞쪽 또는 뒷쪽의 조건에 따라서 검색 방식을 다르게 할 수 있는데, 이걸 매번 까먹네요😥
1. Positive Lookahead
"save me, save me. I need your love before I fall, fall."
.replaceAll("(save me|fall)(?=\.)", "(x2)");
결과는 save me, (x2). I need your love before I fall, (x2). 이렇습니다.
즉, regexp2 가 정방향(읽어나가는 방향)에 있을 경우 regexp1 이 검색 됩니다.
2. Nagative Lookahead
"save me, save me. I need your love before I fall, fall."
.replaceAll("(save me|fall)(?!\.)", "(..)");
결과는 (...), save me. I need your love before I (...), fall. 이렇습니다.
즉, regexp2 가 정방향(읽어나가는 방향)에 없을 경우 regexp1 이 검색 됩니다.
3. Positive Lookbehind
"save me, save me. I need your love before I fall, fall."
.replaceAll("(?<=,)\s*(save me|fall)", "(x2)");
결과는 save me, (x2). I need your love before I fall, (x2). 이렇습니다.
즉, regexp1 가 역방향(읽어나가는 반대 방향)에 있을 경우 regexp2 이 검색 됩니다.
4. Nagative Lookbehind
"save me, save me. I need your love before I fall, fall."
.replaceAll("(?<!(,[ ]))(save me|fall)", "(..)");
결과는 save me, (x2). I need your love before I fall, (x2). 이렇습니다.
즉, regexp1 가 역방향(읽어나가는 반대 방향)에 있을 경우 regexp2 이 검색 됩니다.
conclusion
정리 한다고 했는데, 더 헷갈리게 한건 아닌지 싶군요.
그리고 IntelliJ 나 Eclipse 를 쓰신다면 RegexpTester(http://myregexp.com) 라는 플러그인을 사용해보면 정규표현식 작성에 도움이 될까 싶어요.
정규표현식 자체가 원래부터 많은 규칙들이 얽힌거니까, 우리... 잘 못해도 자신감 잃지 말아요 🤟

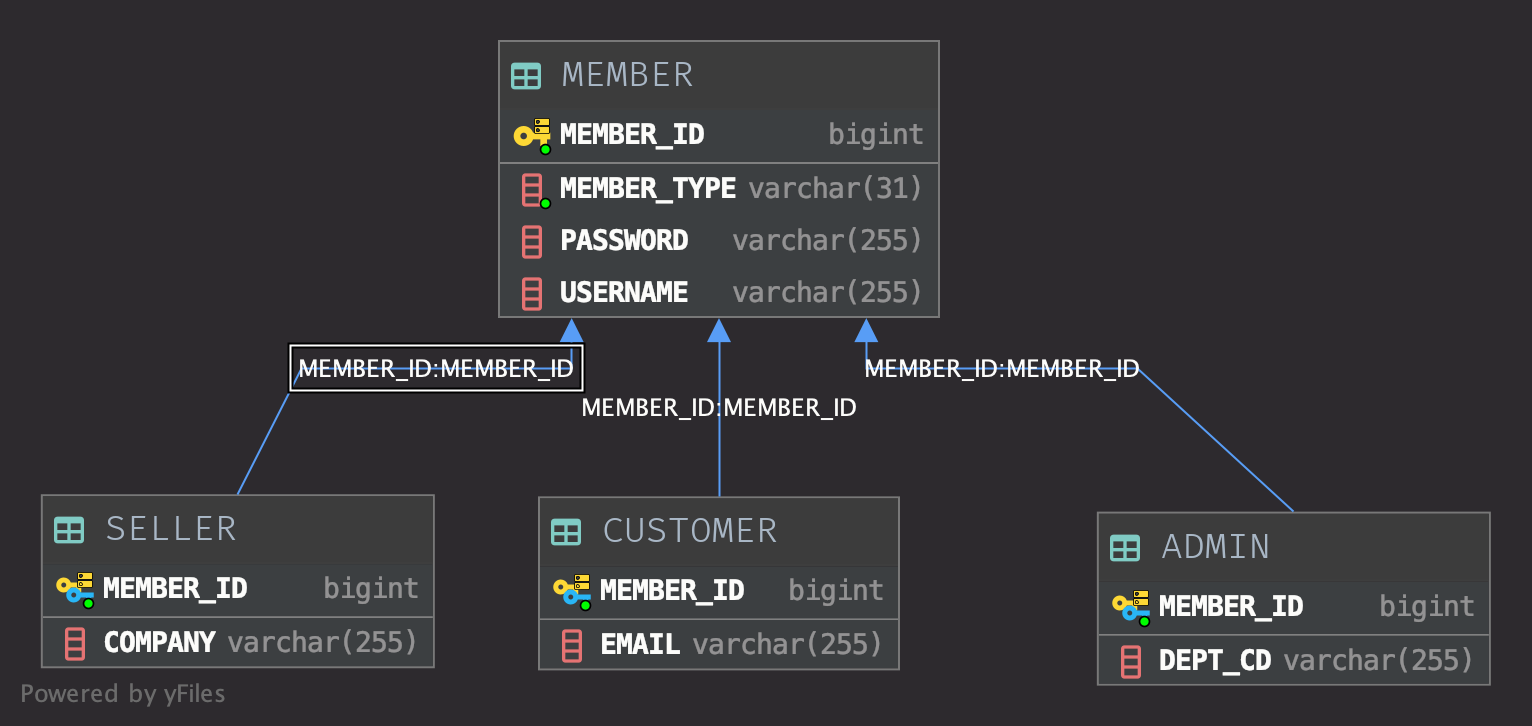
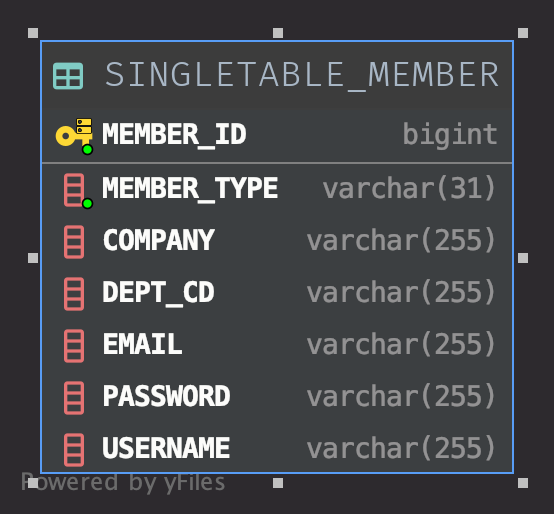
 이렇게 Schema 나옵니다.
이렇게 Schema 나옵니다.